鬼畜学习
相遇皆是缘分
视频展示
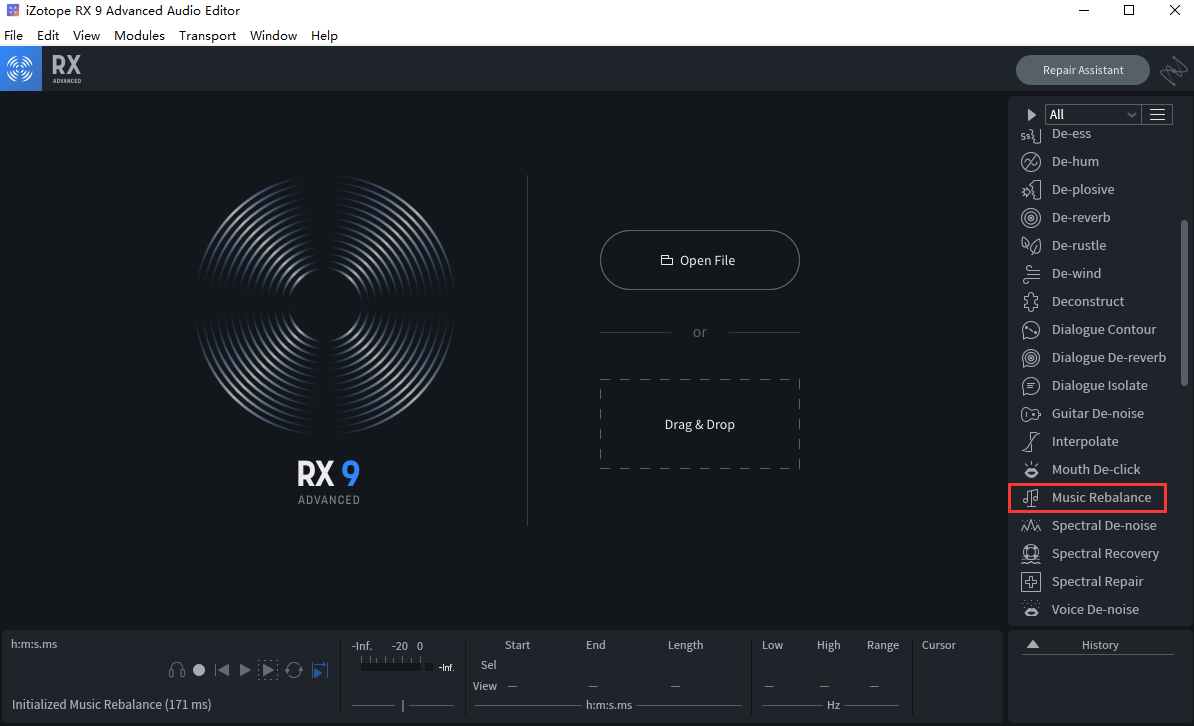
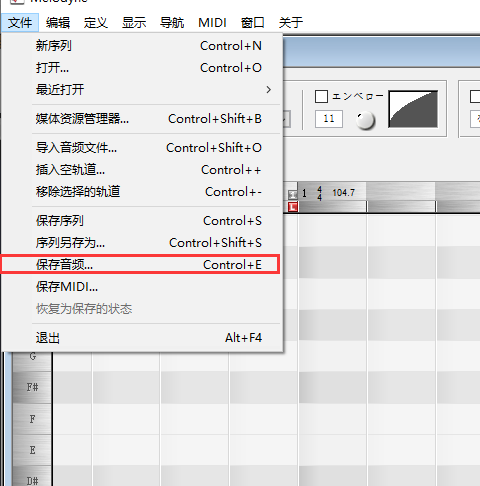
iZotope RX 9
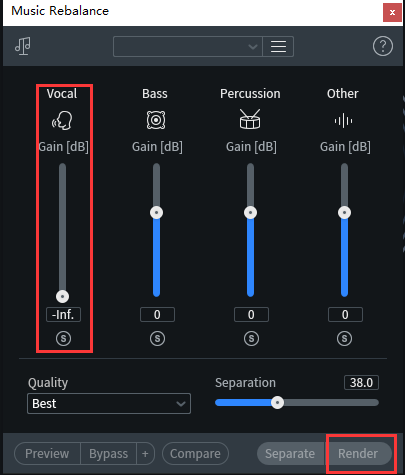
人声分离,去人声,只留伴奏
还可以去伴奏,留人声

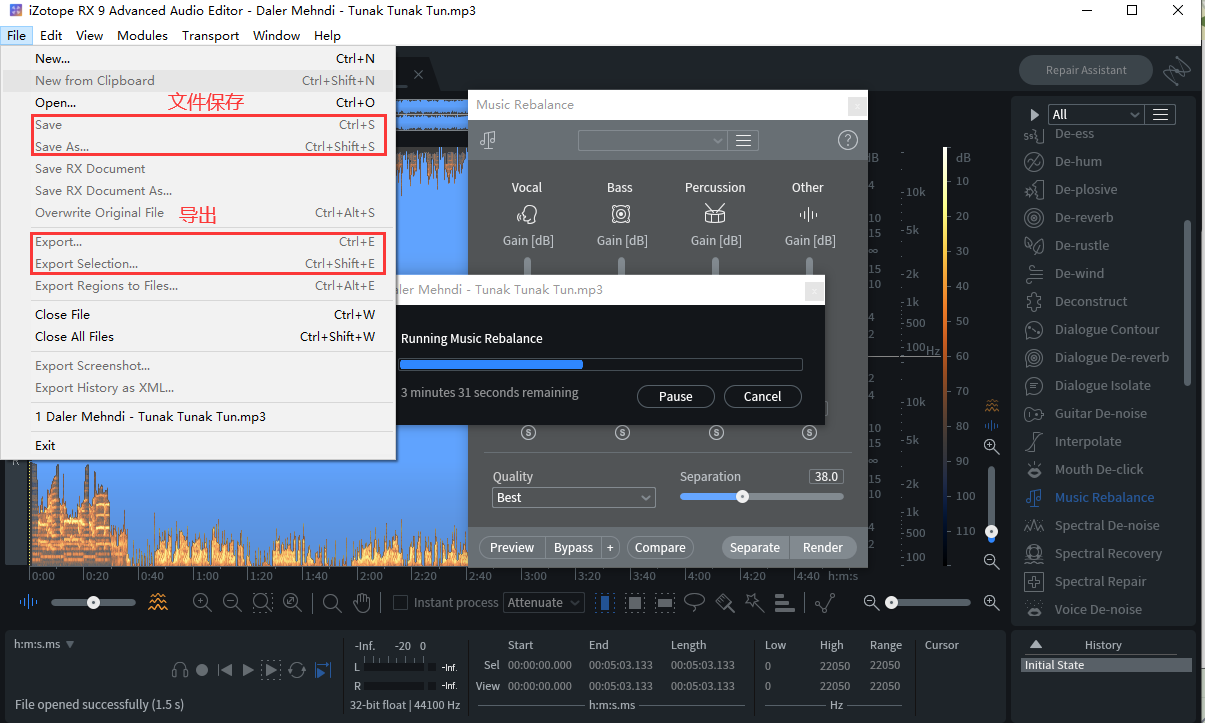
MixM eister BPM Analyzer
测曲速

水果上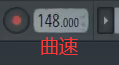
直接将歌曲拖进来,即可查看曲速
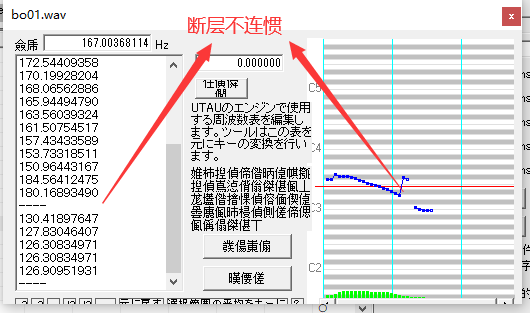
Cakewalk by BandLab
调音/修音 Melodyne插件版
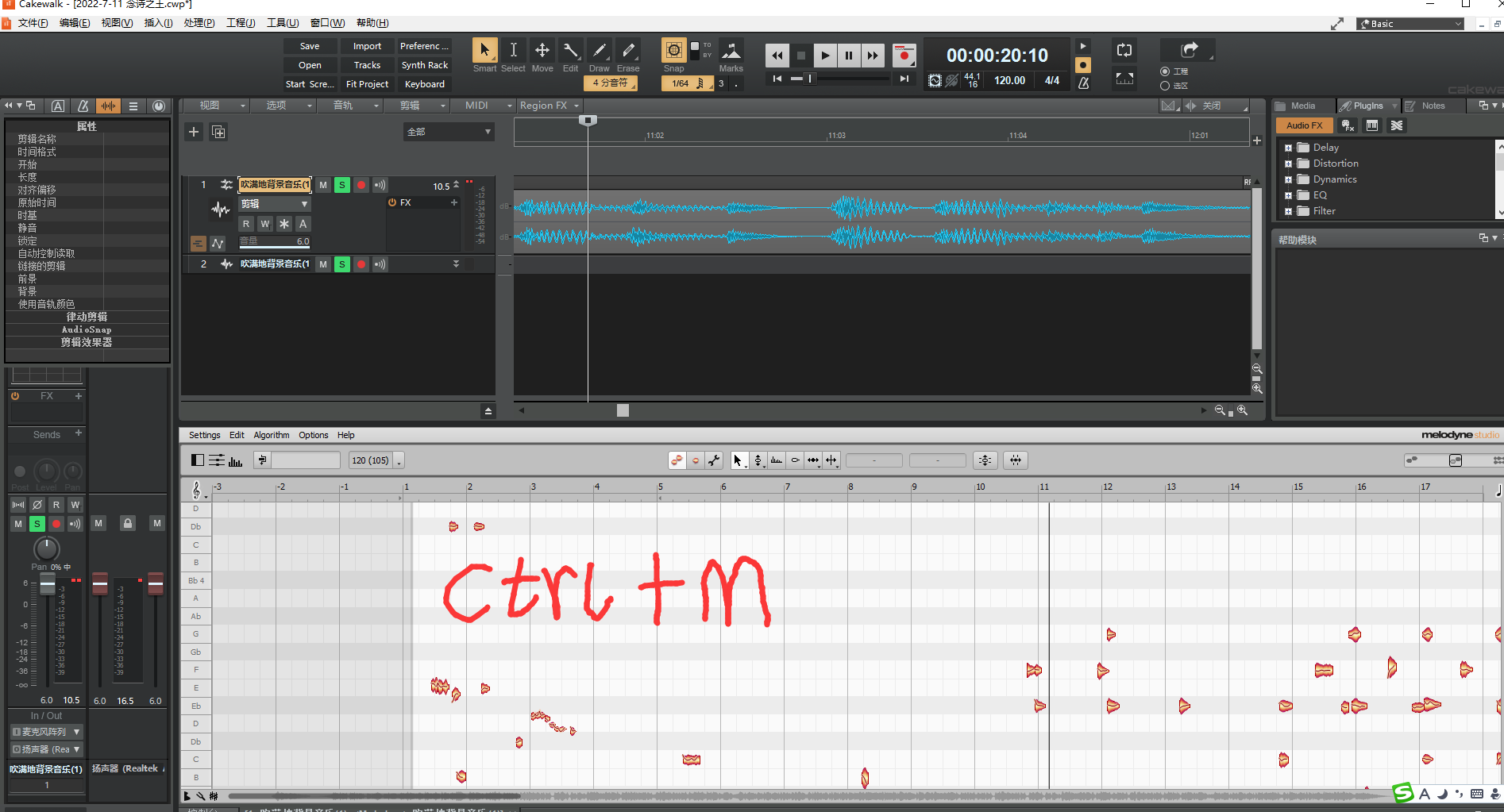
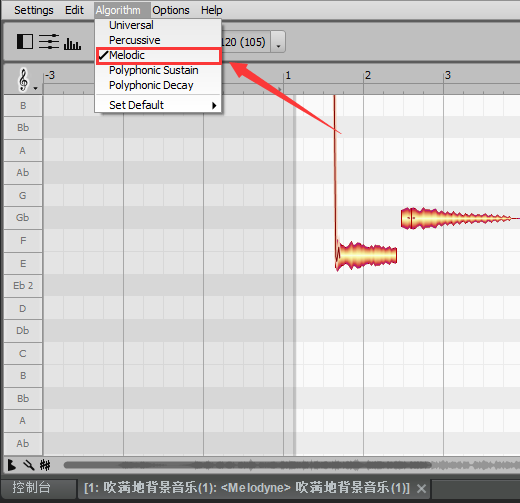
Ctrl+Alt+鼠标左键 绽放干单音区
音调高低
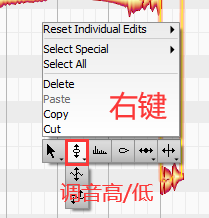
方法:直接选中一个音,上下拖动
转音
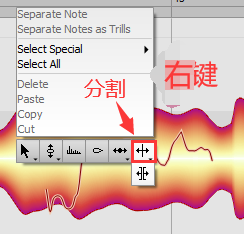
将一个干音,分割成二个或多个
再用 音调高低 方法
音调调节
 、
、
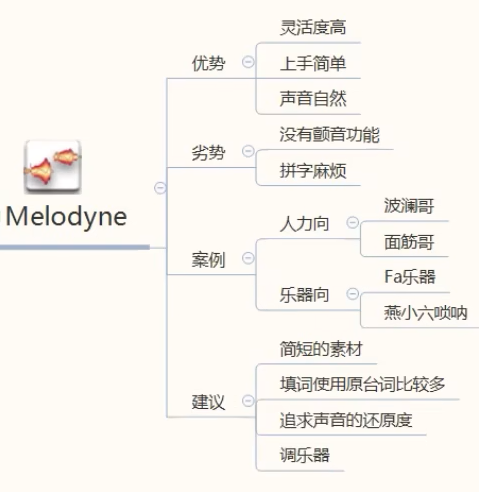
Melodyne(重点)
单独版
优缺
基本用法

变调


时间工具


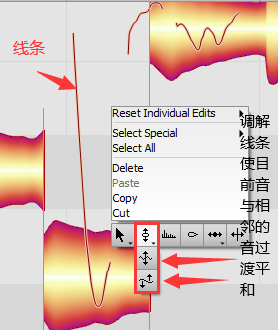
音量、变音、切分操作
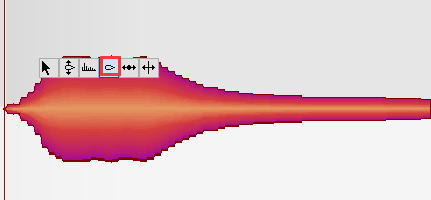

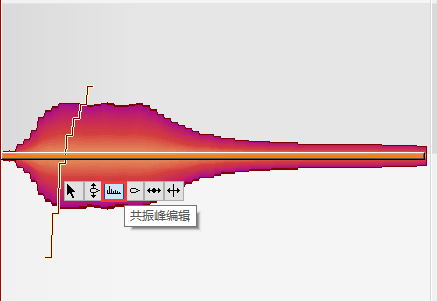

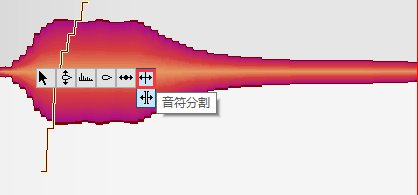
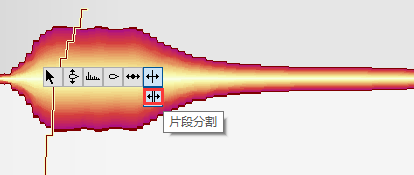

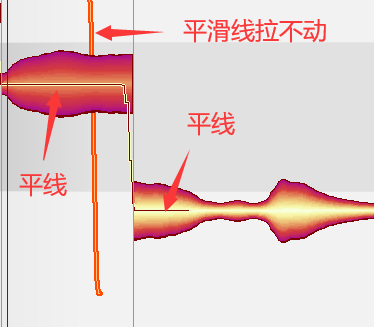
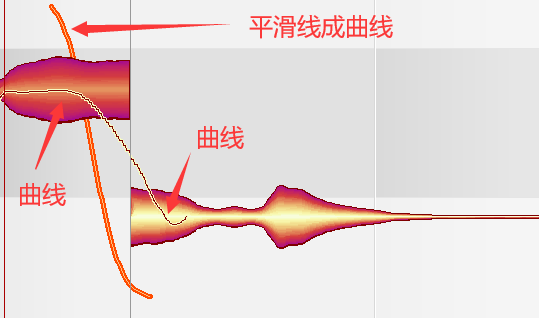
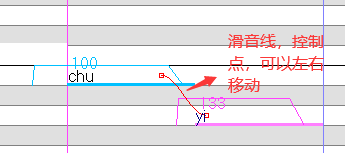
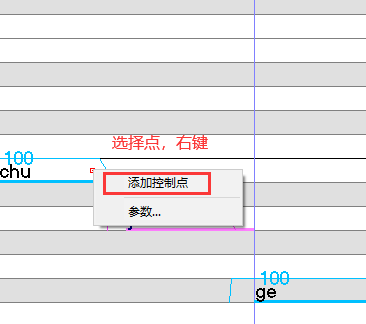
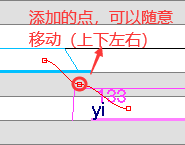
滑音
将两音之间的平滑线拉成平滑曲线

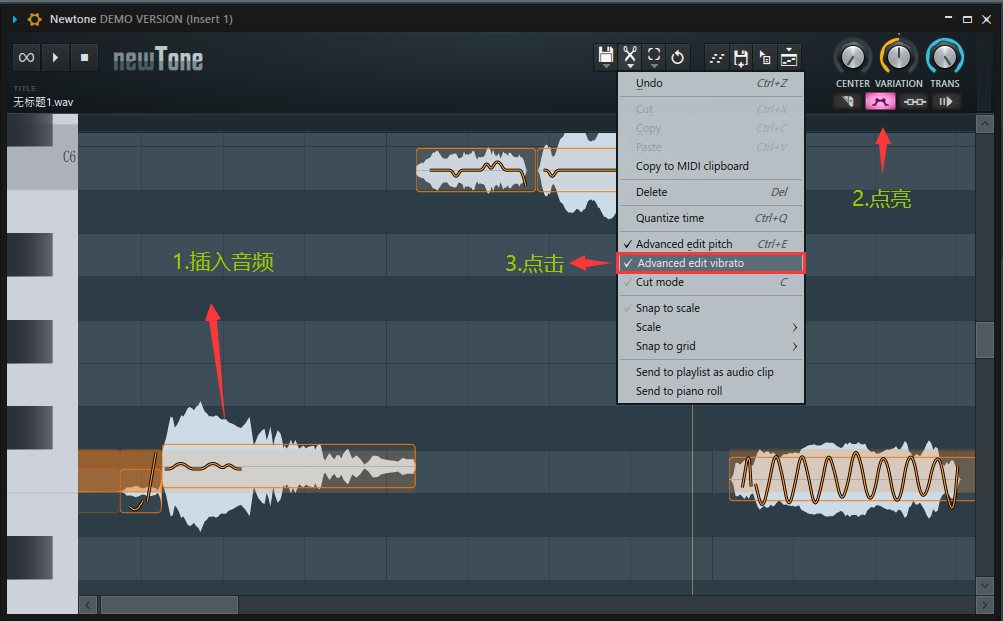
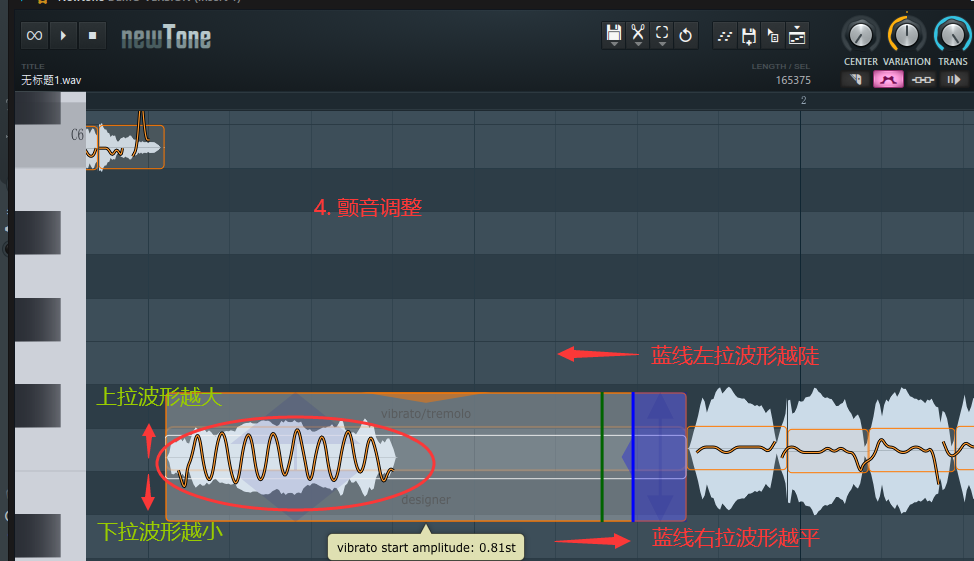
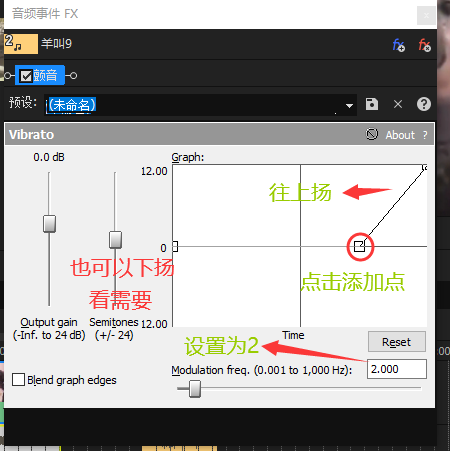
音频加颤音
Waves Tune 插件
水果自带插件 Newtone

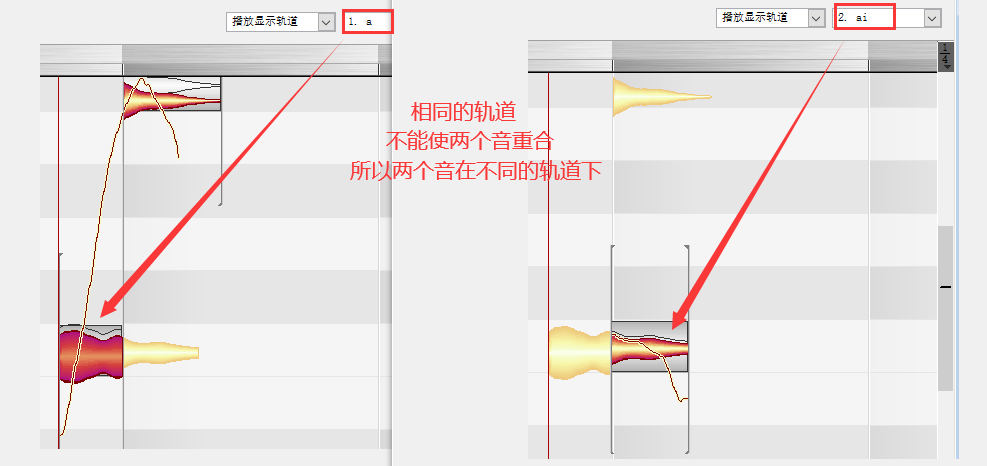
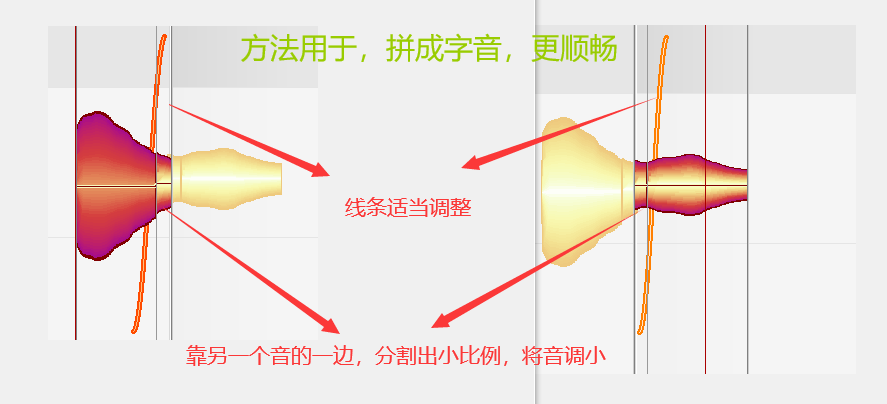
拼字
当截出的字音中,没有某字的音,通过已有的二个或以上的字,拼接为一个想要的字音,比如,拼一个“源(yuan)”字音,可以用“鱼(yu)”字音+“卷(juan)”字音,取“鱼”字音的前面部分+“卷”字音的后面部分
变调算法
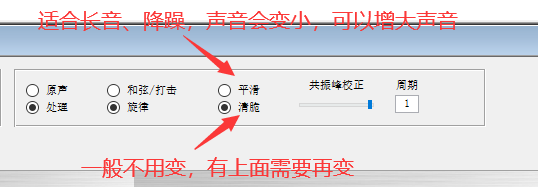
调人声
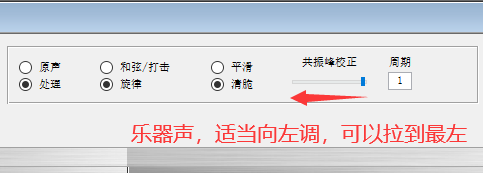
调乐器
鬼畜调音的工作流程
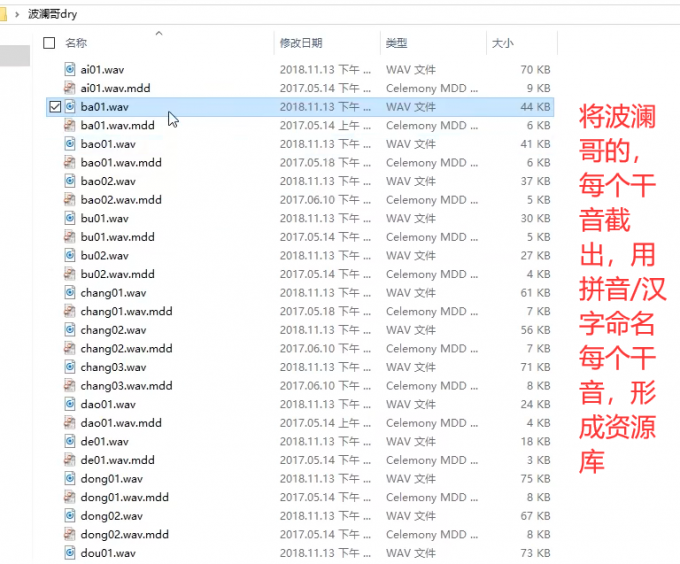
1.建立素材库
2.准备MIDI乐谱(扒谱)
1.一些常用歌曲的MIDI乐谱网上可以查到下载使用
2.Piao Trans 可以将歌曲的MIDI乐谱扒出(有点乱需要自己再调整)— 只用于钢琴声
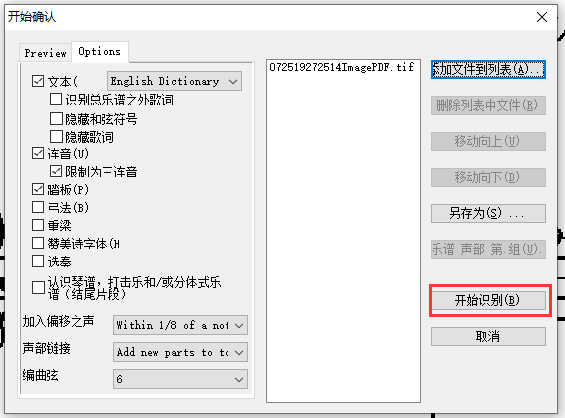
3. SmartScore_pro —五线谱识MIDI谱

1.先去网上找需要歌曲的五线谱(最好是完整的)

转成pdf格式
拖入SmartScore_pro
识别后保存为MID
将保存的MID文件拖入水果或其他软件打开

4.自己用水果扒谱 ---- 有难度需要多多练习
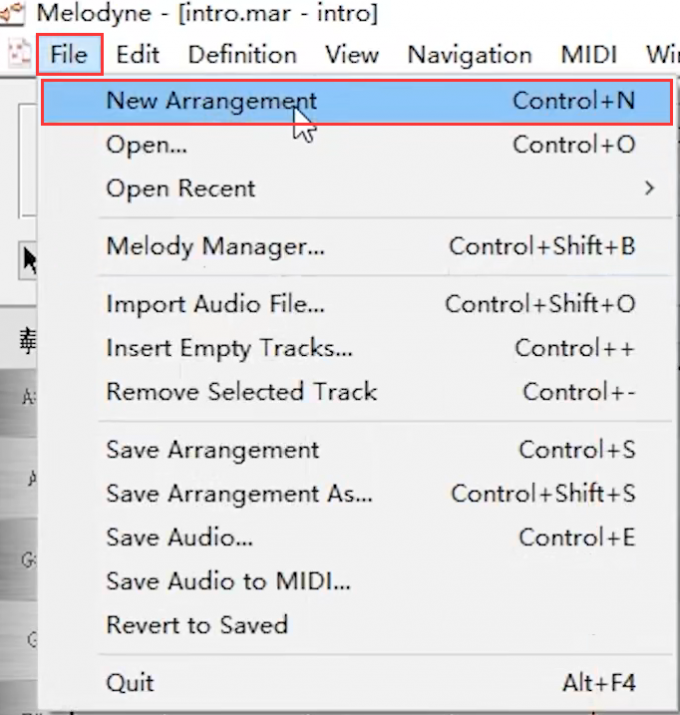
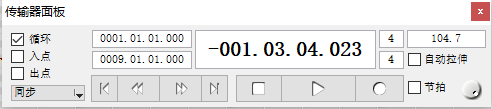
3. 新建Melodyne工程、设置参数
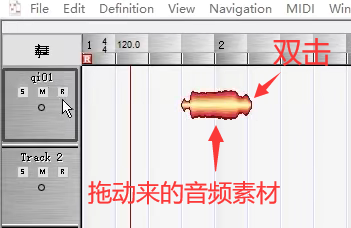

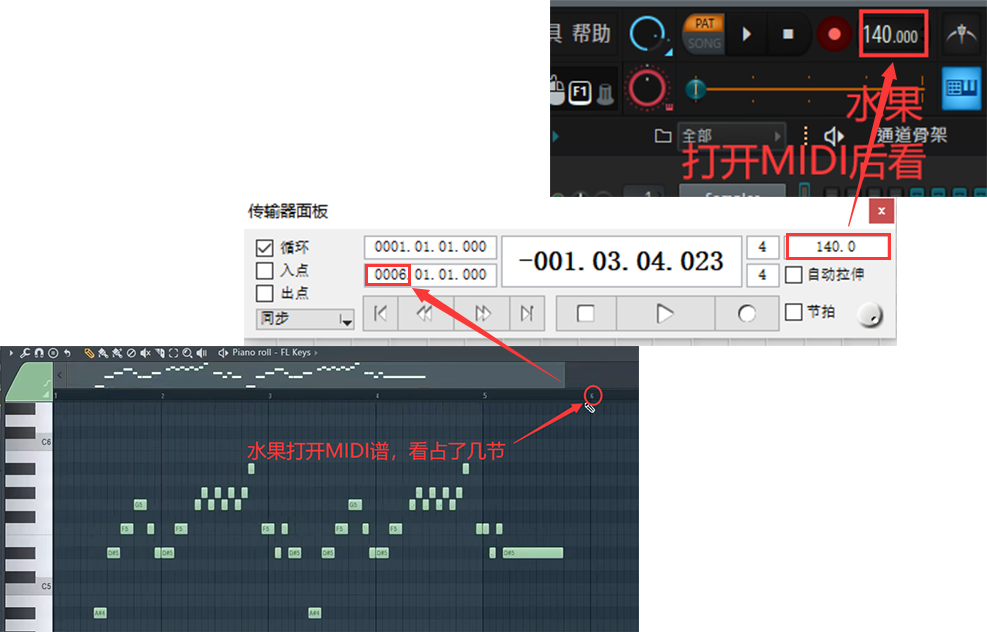
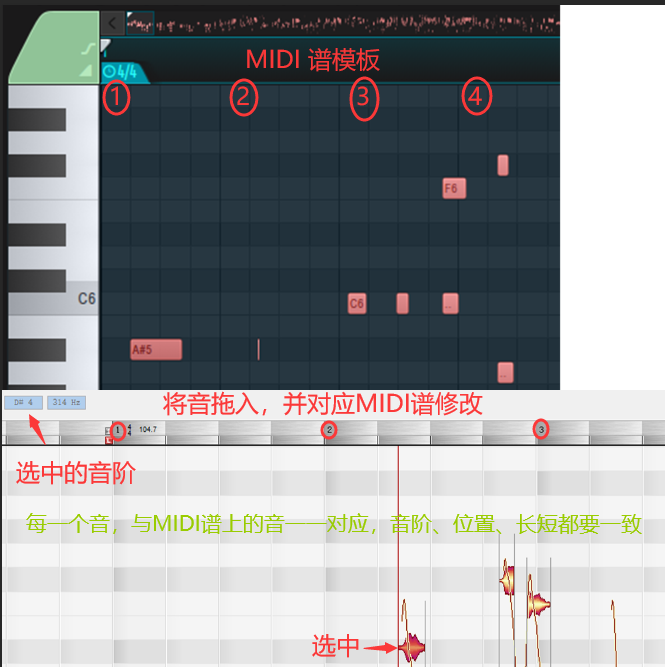
4.参照MIDI调音
5.导出、混音
6.最终效果图
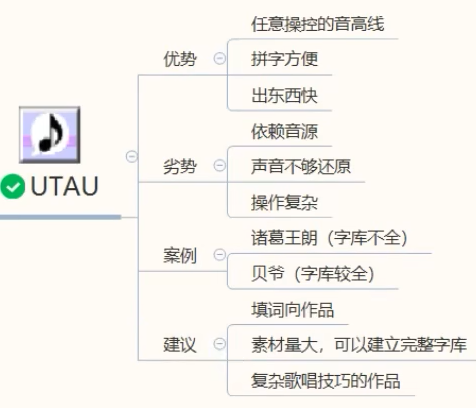
UTAU (重点)
优缺
基本流程
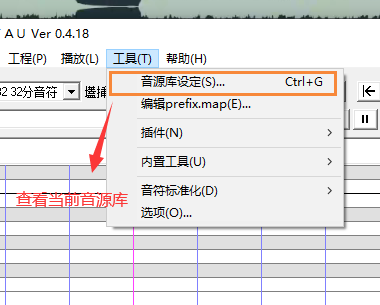
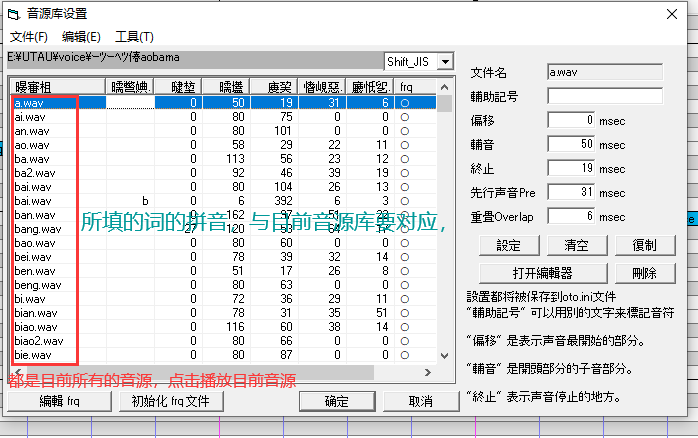
音源制作
建议用AU截取制作音源,当然其他软件也可以
1.先降躁 方法查看 AU

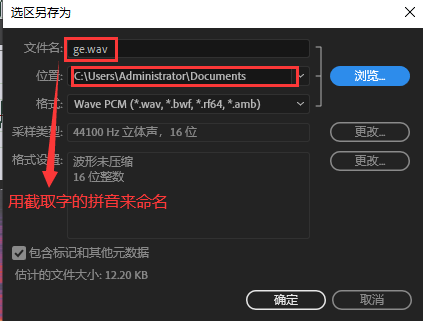
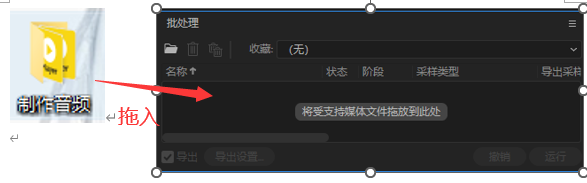
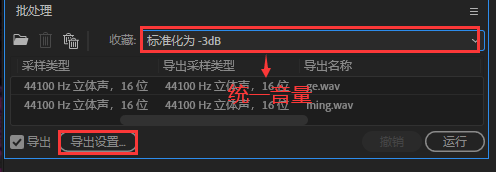
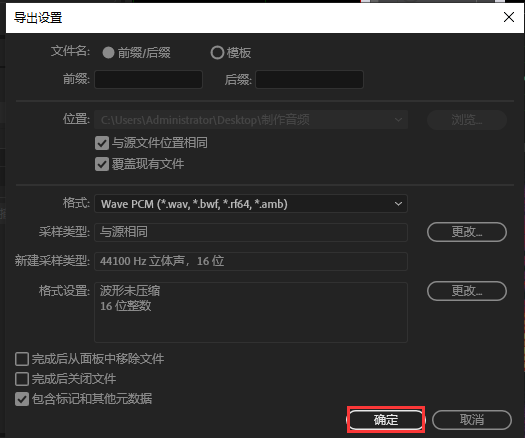

导入MIDI、填词
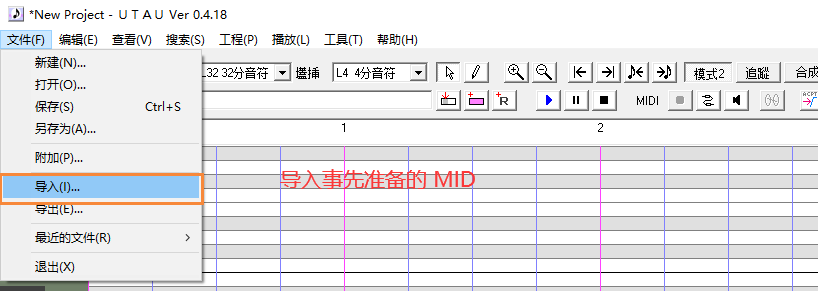
MID 如何制作 查看 Melodyne(重点)----- 鬼畜调音的工作流程 ------- 2.准备MIDI乐谱(扒谱)
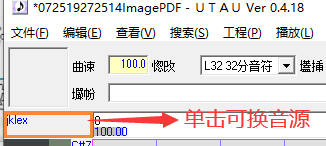
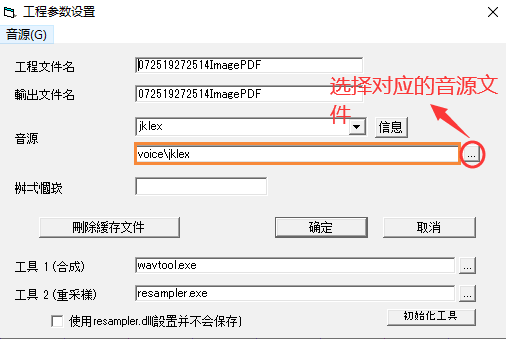
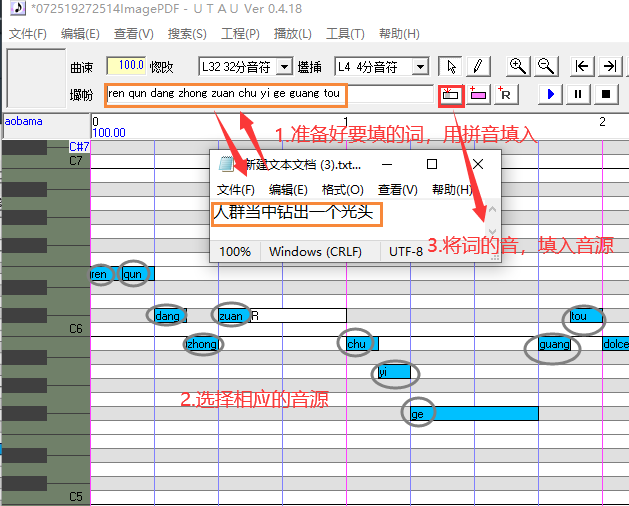
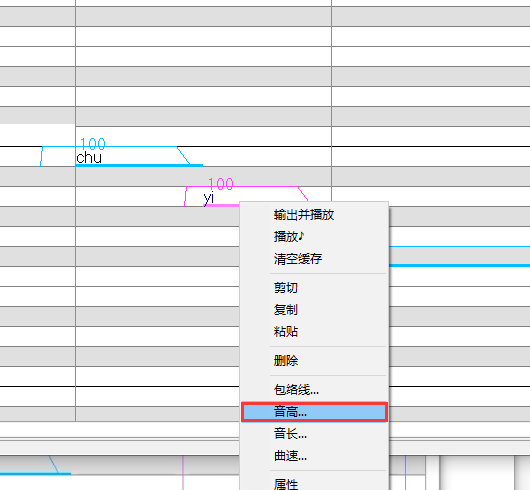
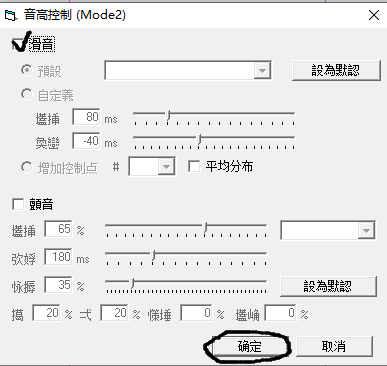
调教
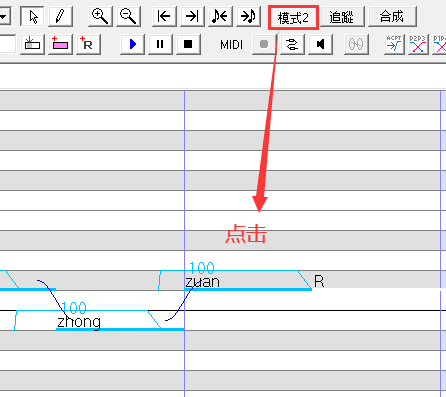
滑音
可以听原曲加滑音,也可以自己加滑音,怎么好听,怎么来
颤音
可以听原曲加滑音,也可以自己加滑音,怎么好听,怎么来
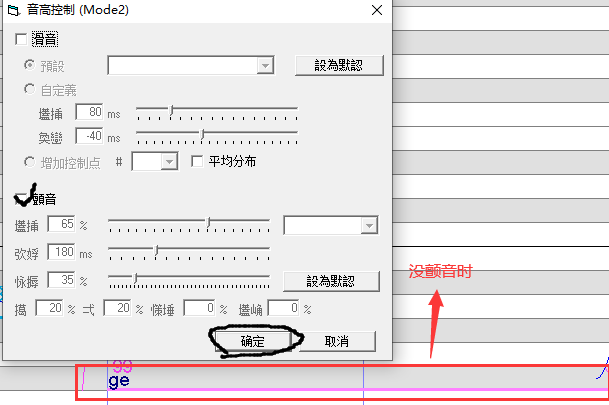
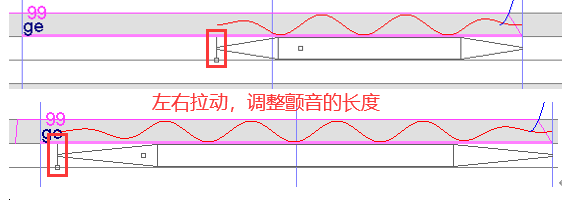
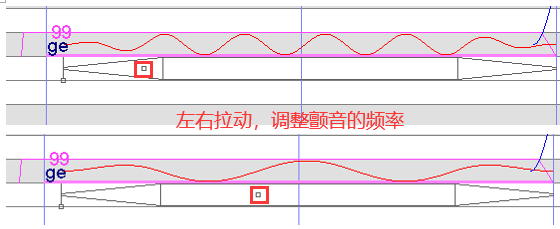
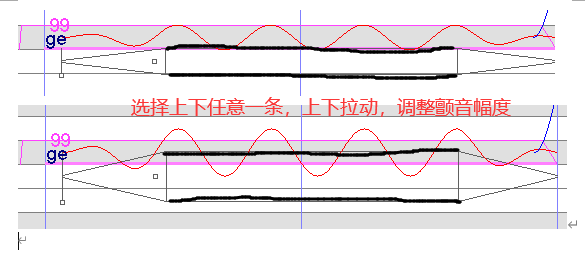
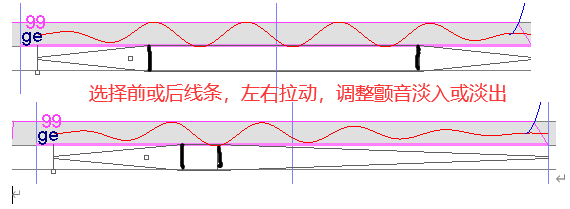
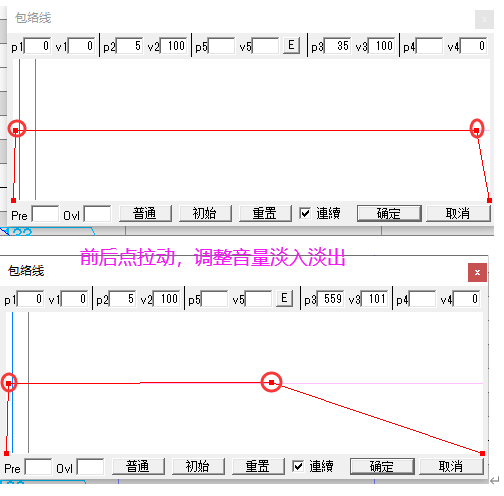
包络
指音量
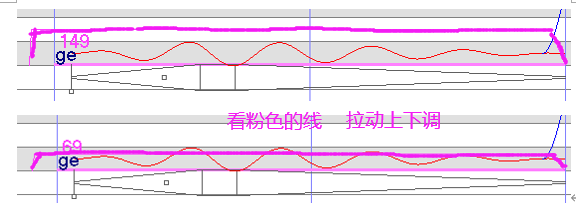
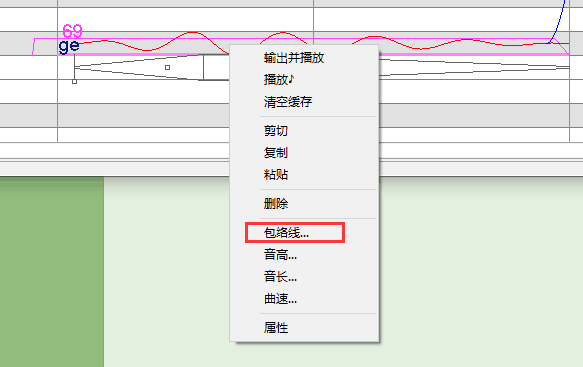
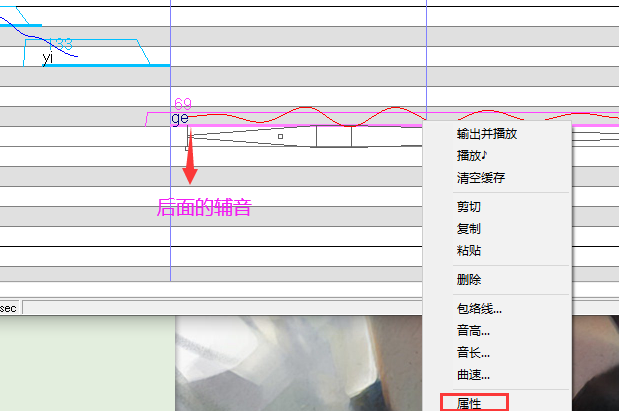
辅音速度
软件里辅音会占用前面一个音的后半部分,有时会导致前面的音很短,不清楚,后面辅音又太长了,很拉夸
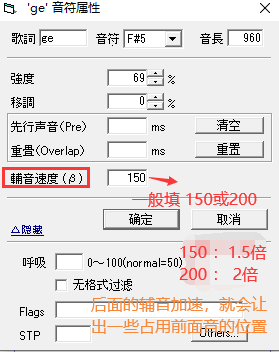
如果前面的音还是很短,就将前面的辅音,也设置为 1.5倍 或 2倍
渲染导出
音源的参数设定











拼字
当截出的字音中,没有某字的音,通过已有的二个或以上的字,拼接为一个想要的字音,比如,拼一个“源(yuan)”字音,可以用“鱼(yu)”字音+“卷(juan)”字音,取“鱼”字音的前面部分+“卷”字音的后面部分







音源的优化和频率修复




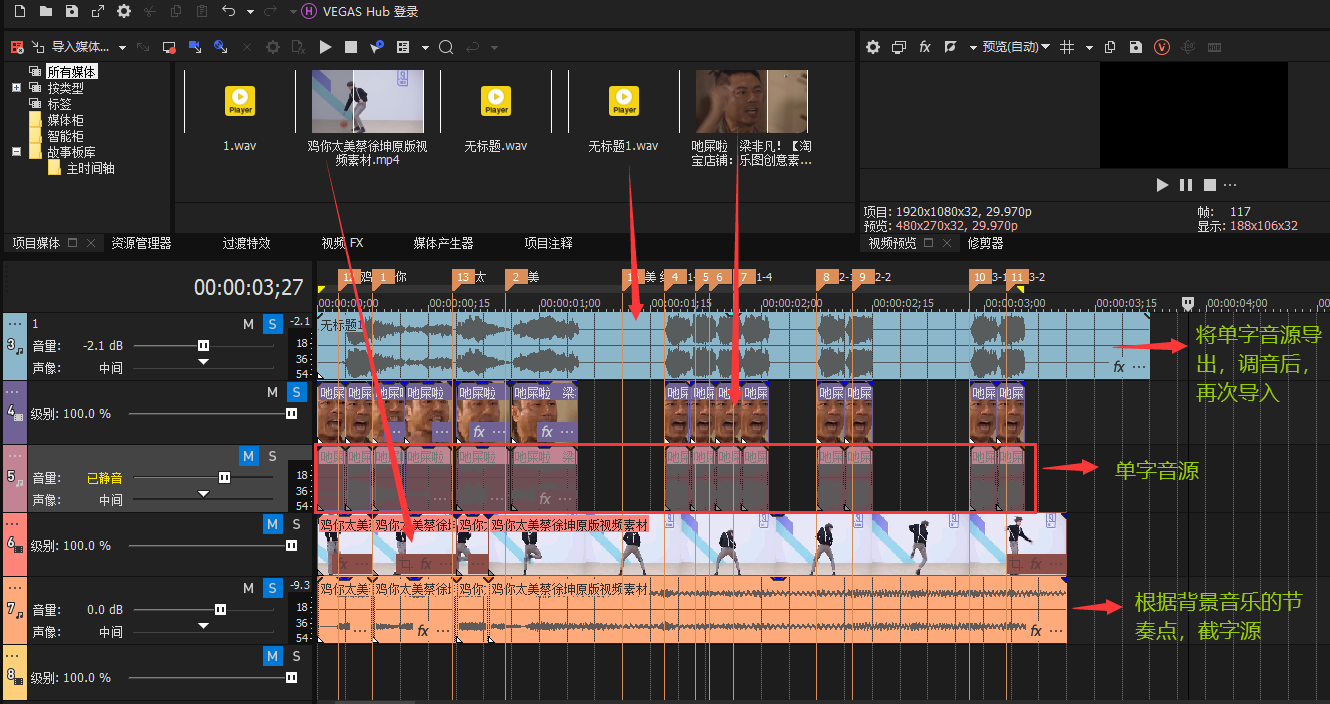
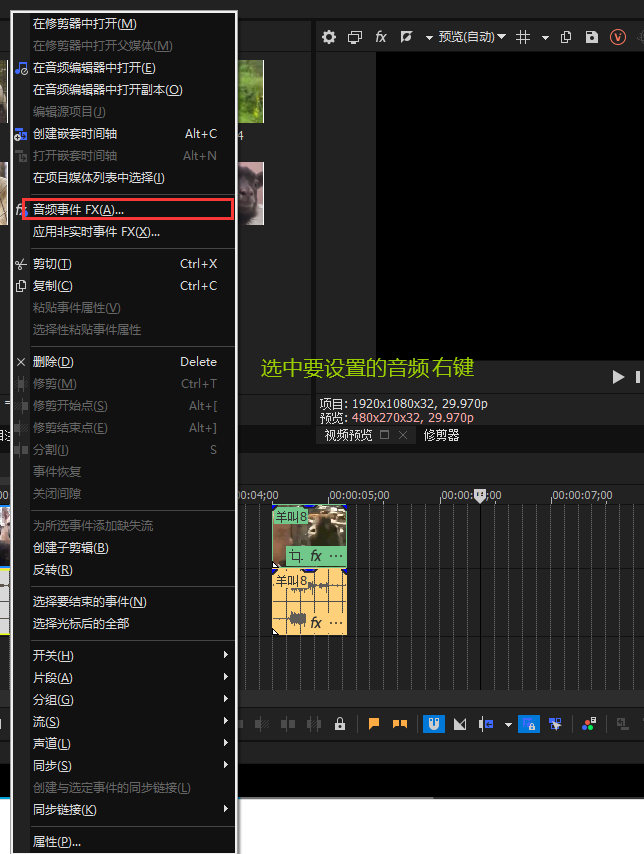
VEGAS
单字拉伸
1 | 原素材的0.5倍 < '拉伸的长度' < 原素材的两位 |
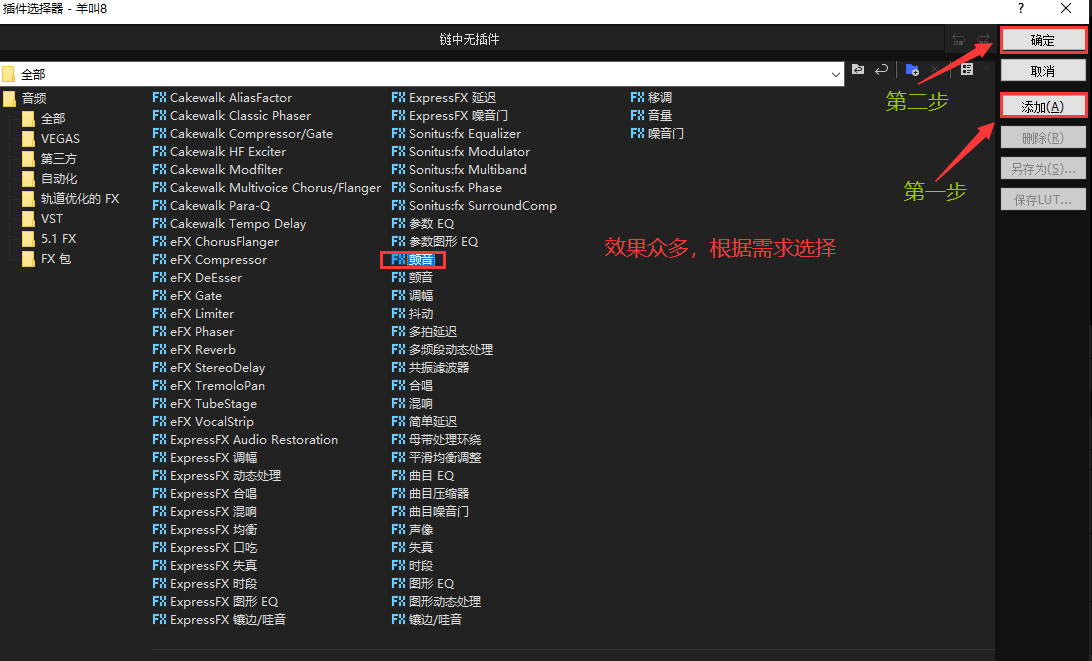
音频效果 - 颤音等等
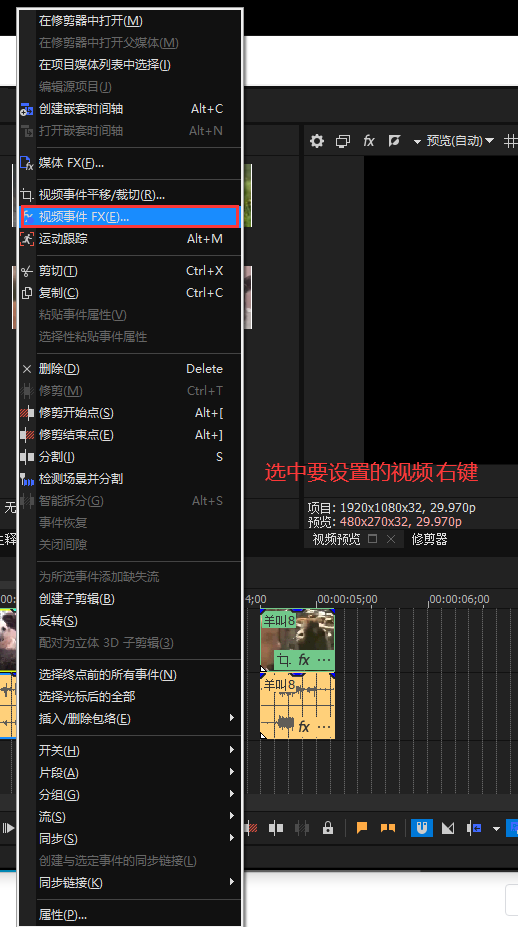
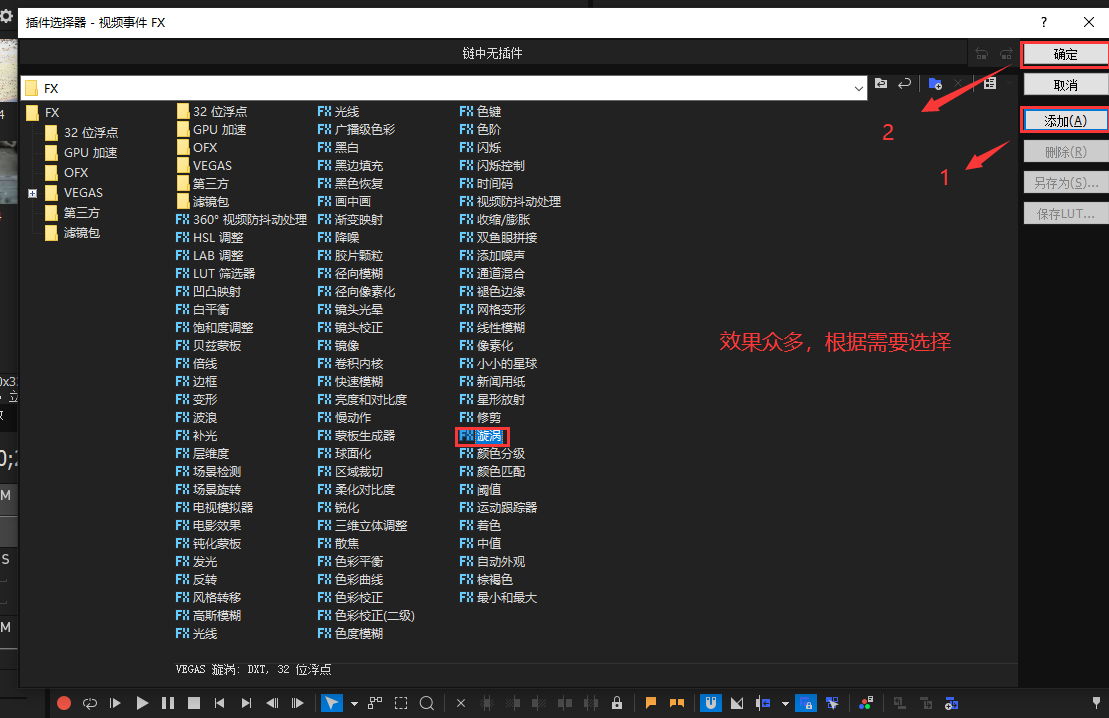
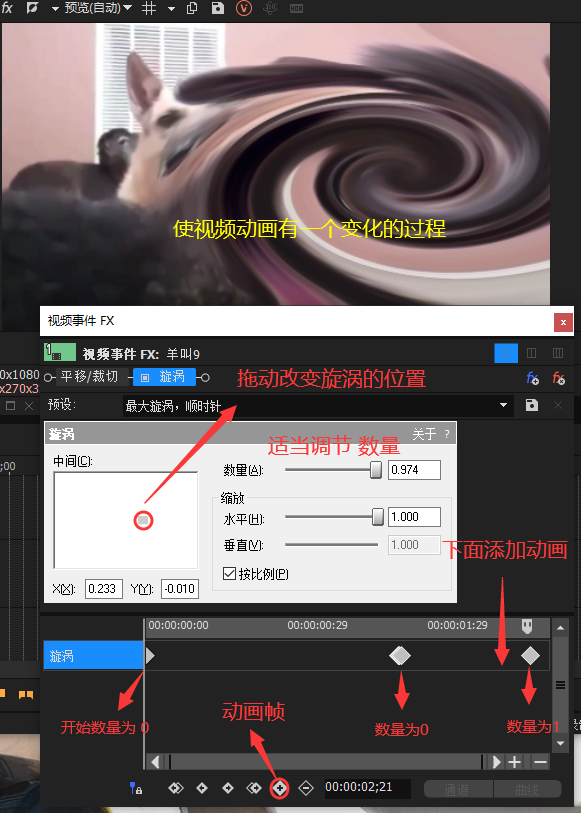
视频效果 - 旋涡、黑白等等
简单混音
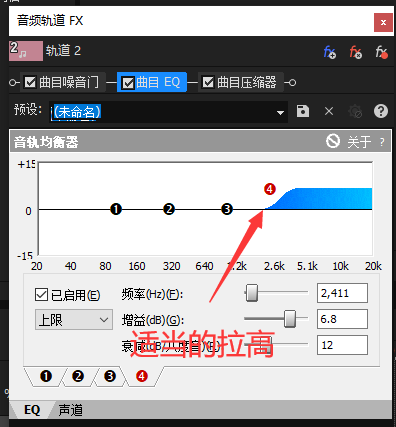
EQ调整
优化听感
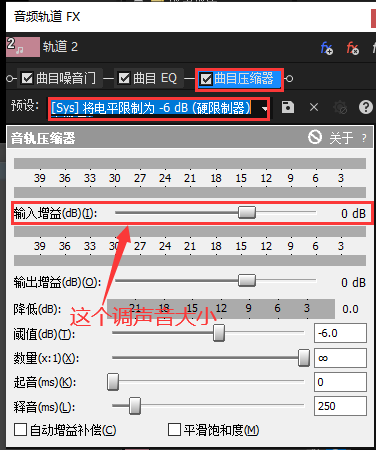
限制器
防止声音爆音
混响
调音可能失真,混响修饰
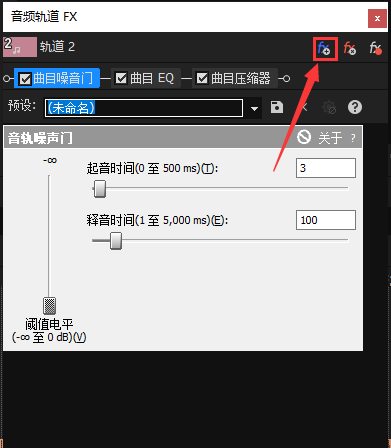
ExpressFX 混响
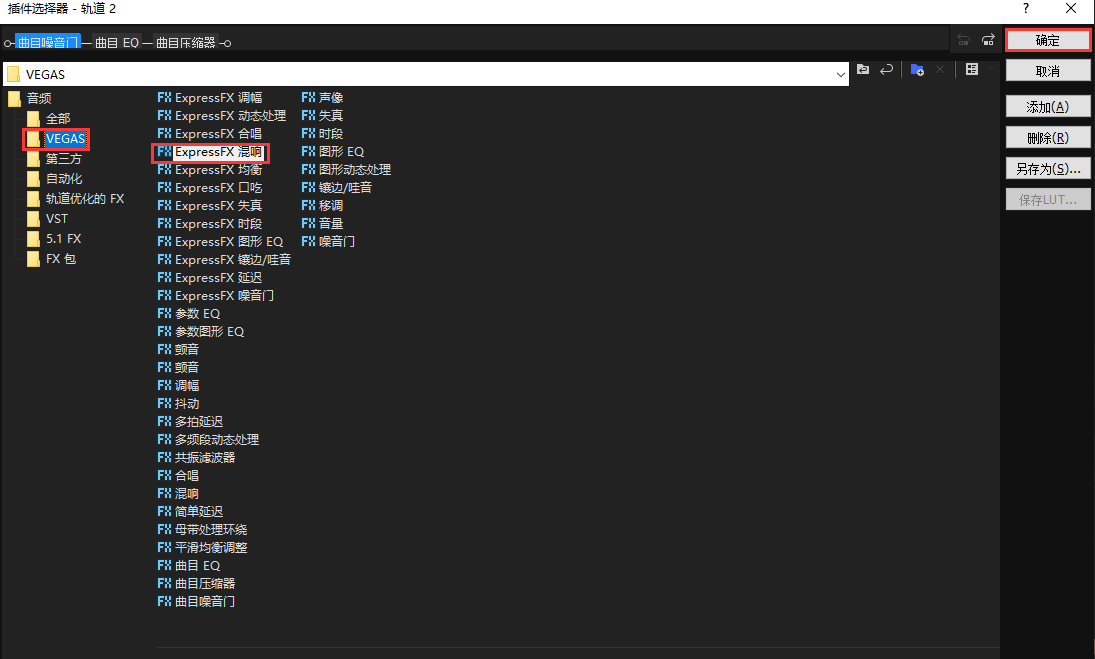
和声
简单和声 (低八度垫唱和声法) 中高频声 变浑厚一些
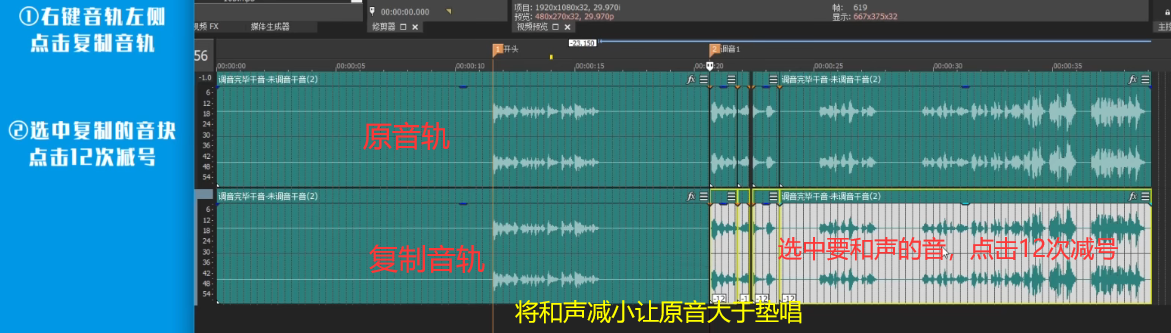
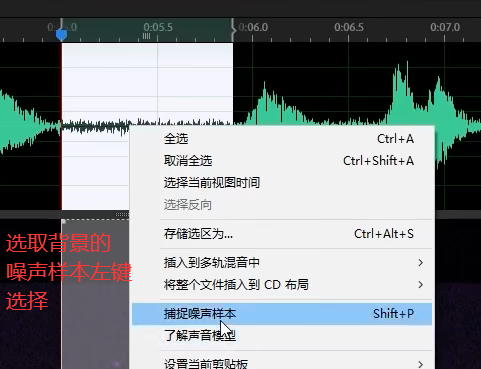
AU

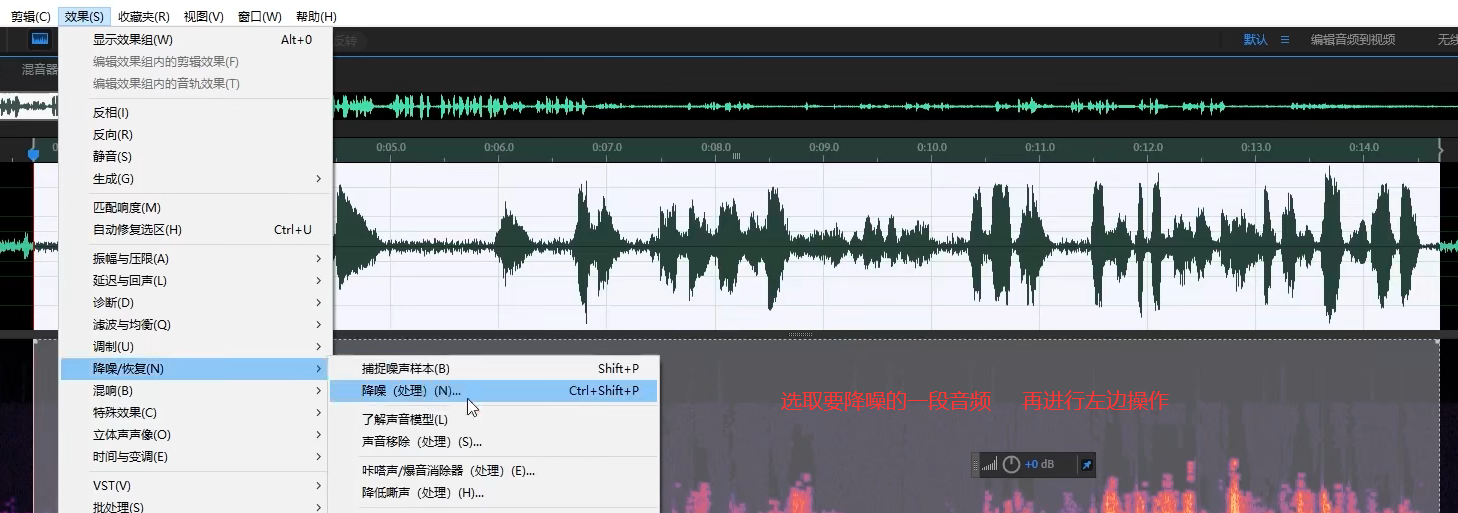
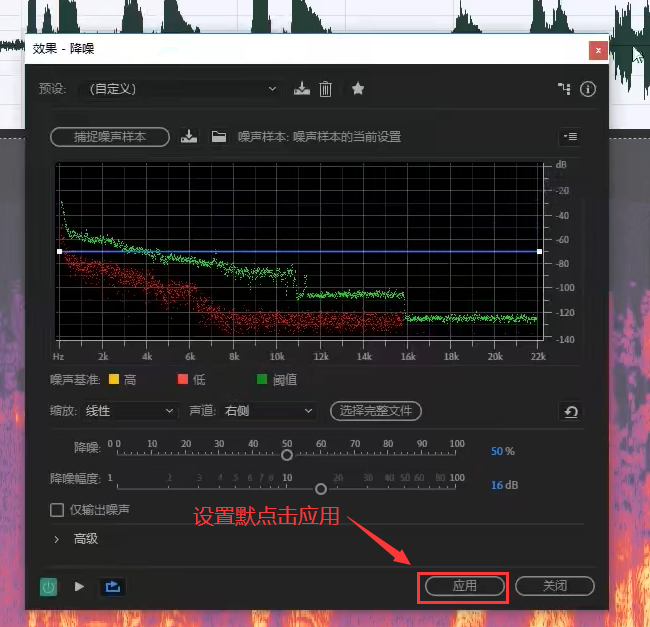
降躁
运用于音频有背景躁音
AI人声模拟
可以模拟任何真人声音,不过需要大量训练模型(请勿乱用)
源码及教程
基本用法
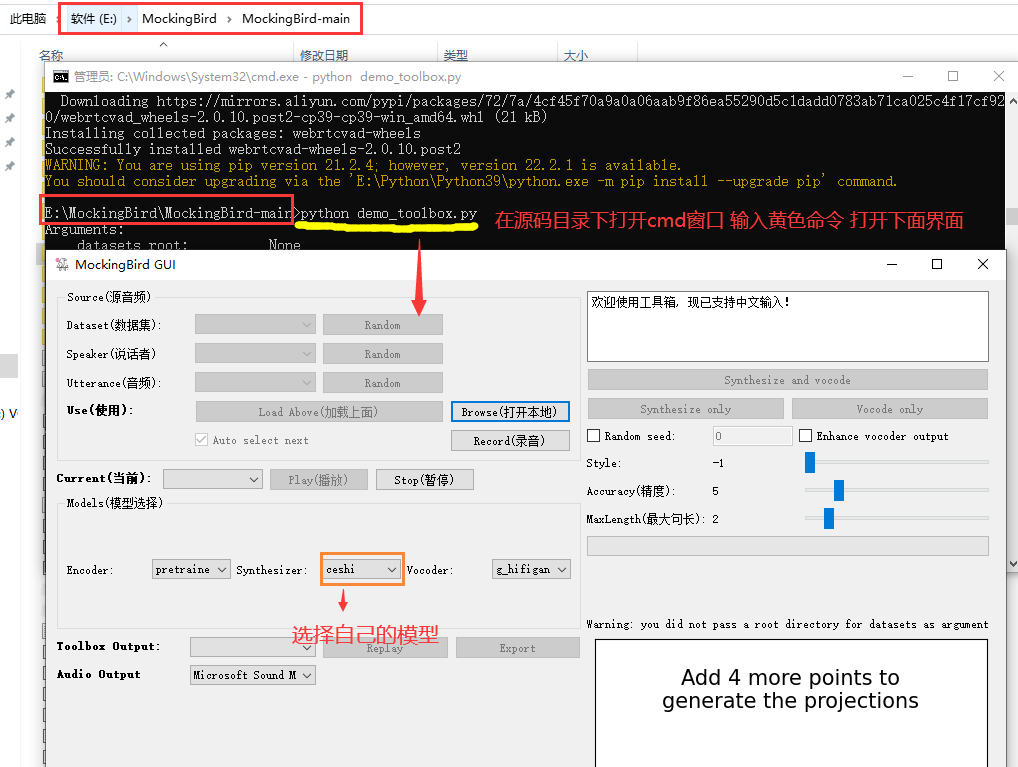
打开界面
1 | python demo_toolbox.py |
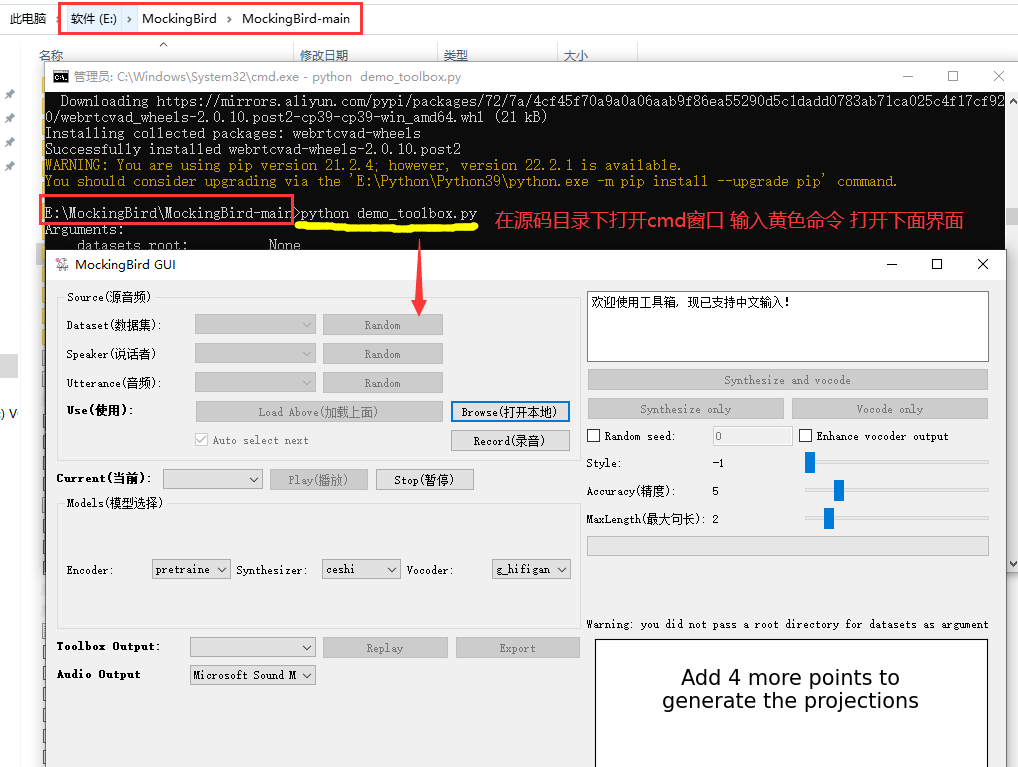
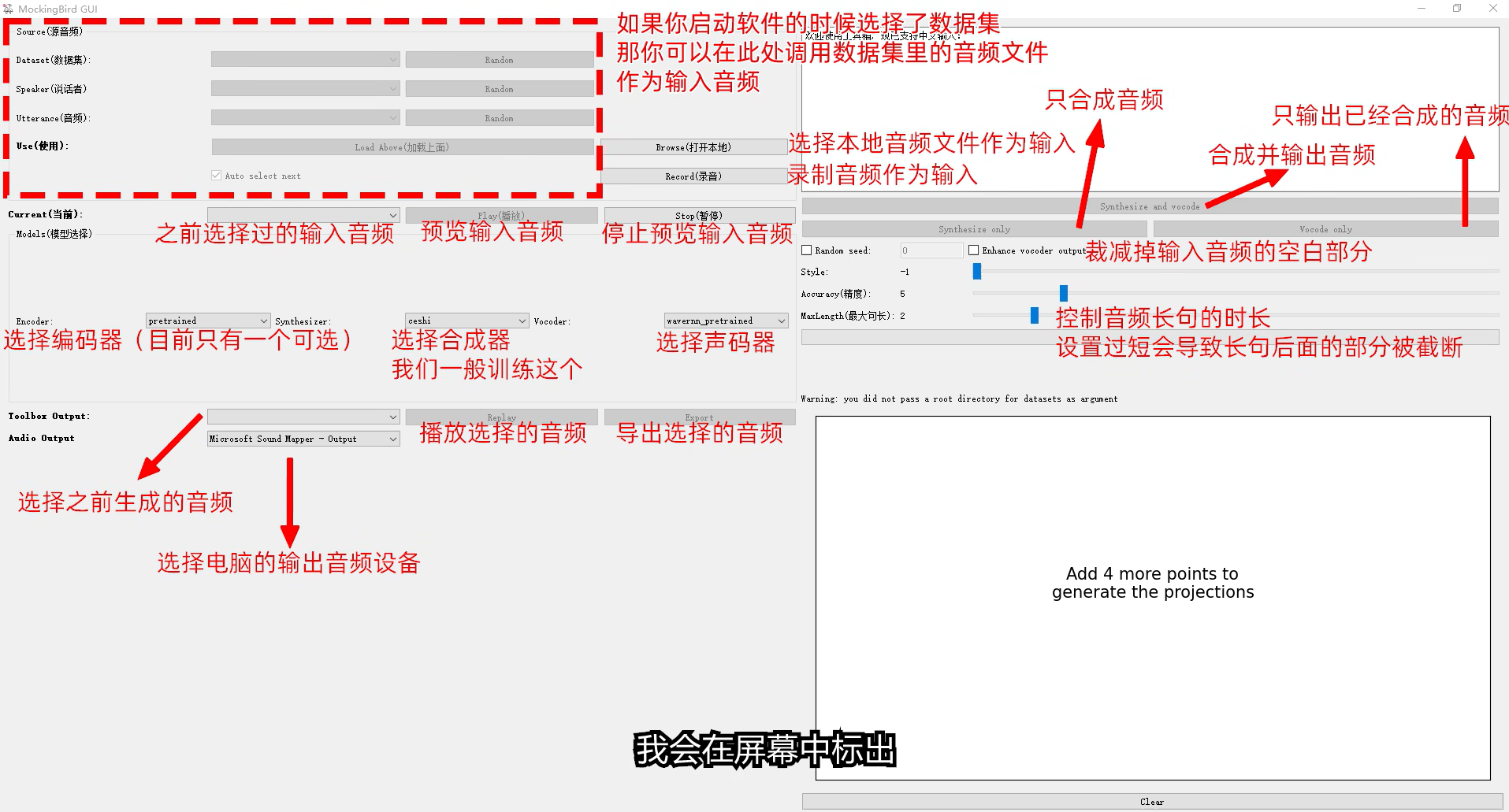
界面功能
AI 模型制作流程
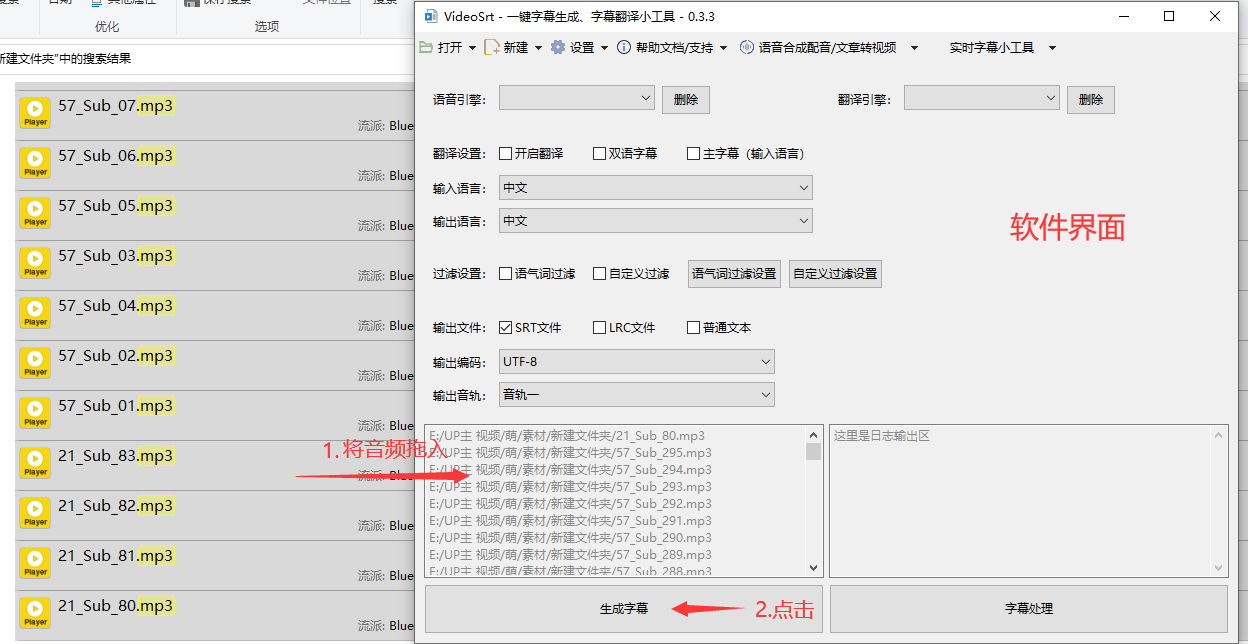
videosrt(音频识别文字)
将多个音频识别成文字,并输出到txt文本
- 给所有音频生成文本 格式为 SRT文件 (语音引擎:阿里云 自己配)
2.存放音频和文本
2.1音频
2.2文本
3.生成音频文字
1 | python long_file_cut_by_srt.py |
4.听音频校对文本
文本与相应的音频不对就更改,音频不清楚导致文本差错大,可以把该行文本删除,保证几百行没大问题
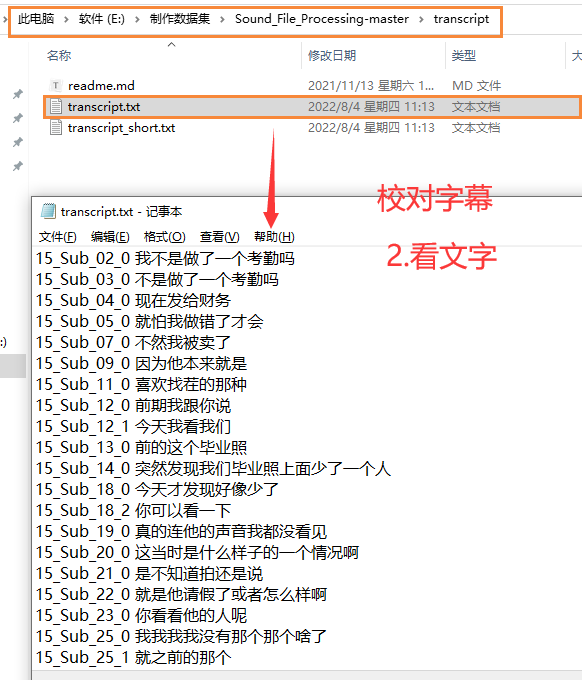
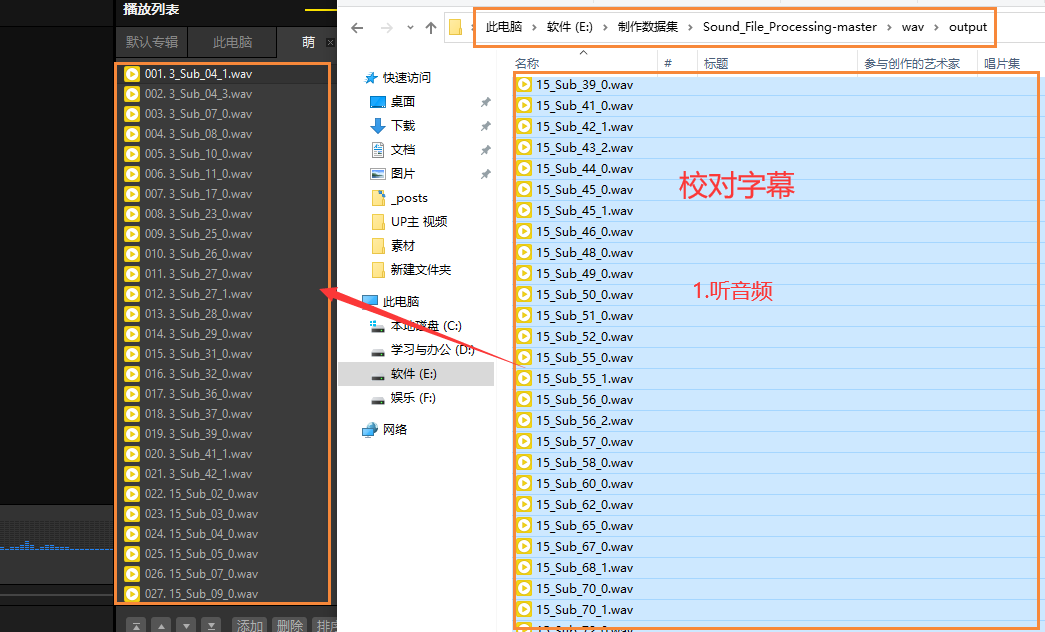
5.校对完毕,移植
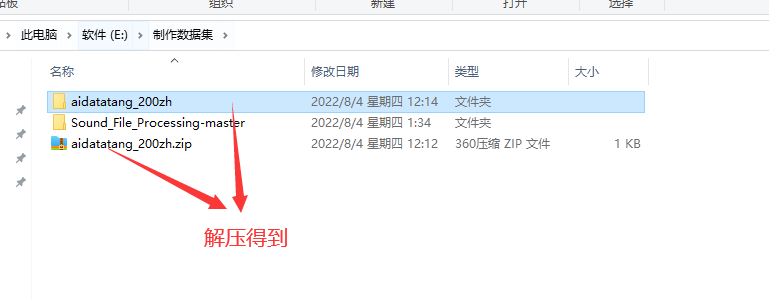
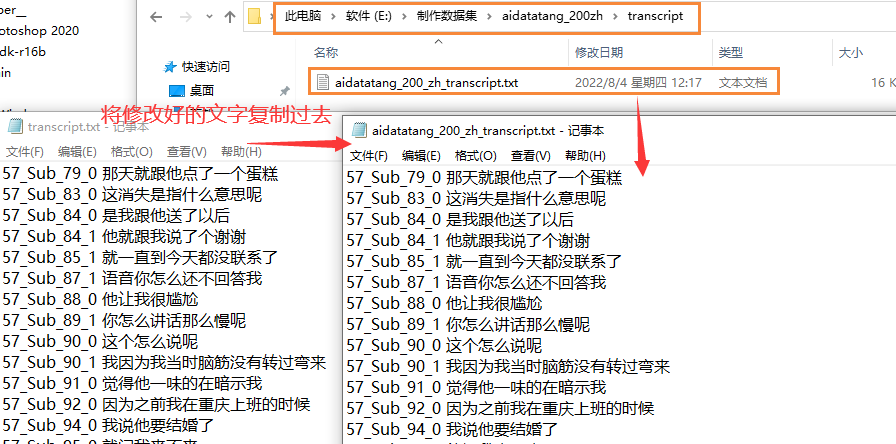
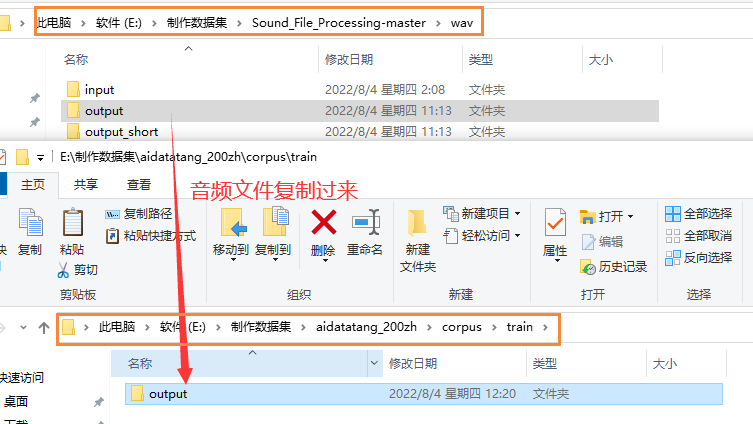
6.生成模型命令
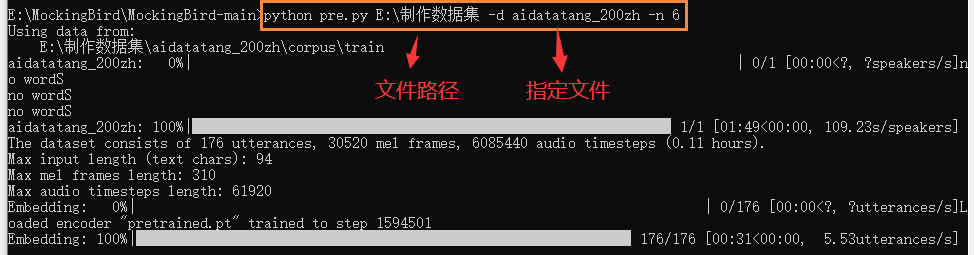
1 | python pre.py <datasets_root> -d {dataset} -n {number} |
1 | python synthesizer_train.py mandarin <datasets_root>/SV2TTS/synthesizer |
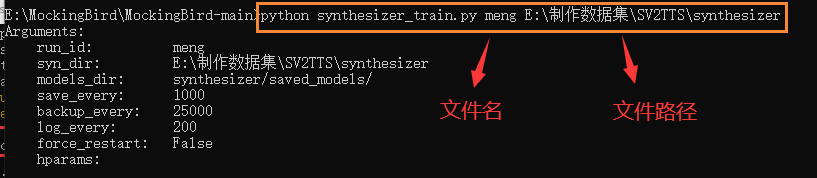
数据小,执行命令几分钟后,ctrl+c 终止
用原作者公开的已有模型,改成自己模型的名称,代替,并再次执行命令,执行几个小时后,查看plots文件是否有音频图,有,证明有效果,运行完数据量太大, 几个小时后,终止即可
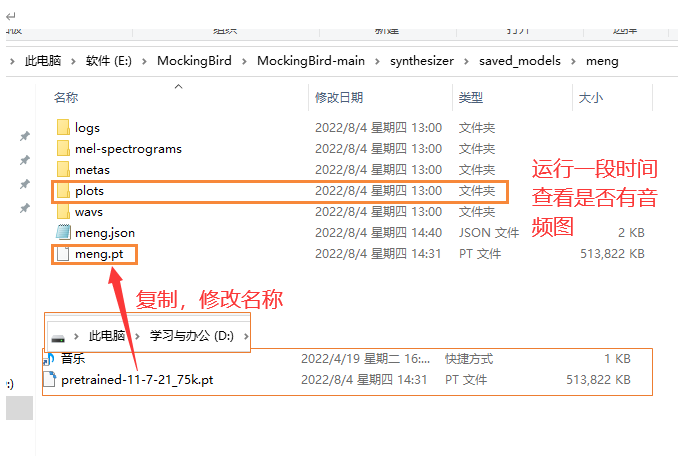
6.将自己的模型放入模型库
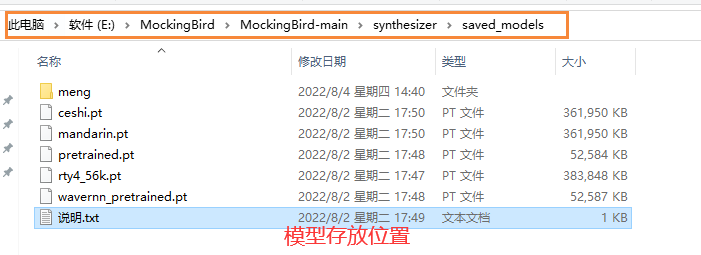
7.运用自己的模型(详细查看 基本用法)
1 | python demo_toolbox.py |
鬼畜RAP
乐器